- はじめに
- この記事でできること
- 01. テーブルとは何か|「範囲」と「テーブル」の決定的な違い
- 02. Ctrl+Tで30秒でテーブル化|最速の変換方法
- 03. テーブルの4つの自動機能(基本)|テーブルのメリットが一目瞭然
- 04. 構造化参照で数式をシンプルに|合計・平均の実例
- 05. SUBTOTALとの組み合わせ(目から鱗)|フィルター後も正確に集計
- 06. スライサーで高級ダッシュボード化|複数テーブルに同じボタン適用
- 07. テーブル + ピボットテーブル の無敵コンボ|ソーステーブルの変更が自動反映
- 08. 実務マルチシーン活用例|名簿・落札・在庫での合計・平均・カウント計算
- 09. テーブル解除・一時的な範囲変換|加工後の調整方法
- 10. よくあるエラーと対処法|万が一のときも慌てない
- まとめ|テーブル機能は「今やるか後でやるか」の選択肢
はじめに
Excelを使っていて、こんな経験はありませんか?
データを追加するたびに、行の計算式をコピーし忘れる。フィルターをかけたら合計がおかしくなる。複数のシートから同じ条件で抽出して比較したい。数式が複雑で、6ヶ月後には何をしてるのか分からなくなる——。
ですが、ご安心を。これらのストレスを一気に消す機能が、テーブル機能です。
多くの人は「テーブルって、データに色を付けるだけでしょ?」と思っています。でも違うんです。テーブルは「自動化の仕組み」 です。一度テーブル化すれば、新しい行の追加、数式の継承、フィルター後の正確な集計——すべてが自動で動きます。
この記事では、テーブルの基礎から応用まで、実務で即座に役立つテクニックを徹底解説します!
この記事でできること
この記事は、初心者から中級者向けに設計されています。
- 基本的な使い方を知りたい → 「01. テーブルとは何か」から「03. テーブルの4つの自動機能」までをお読みください
- 数式を最適化したい → 「04. 構造化参照で数式をシンプルに」と「05. SUBTOTALとの組み合わせ」が役に立ちます
- 会社でドヤれるダッシュボードを作りたい → 「06. スライサーで高級ダッシュボード化」と「07. テーブル + ピボットテーブル」をチェック
- 実務ですぐに活かしたい → 「08. 実務マルチシーン活用例」で、名簿や落札情報、在庫データの具体例を確認してください
全部読めば、テーブル機能をフル活用できるようになります。ぜひ、最後までお付き合いください!
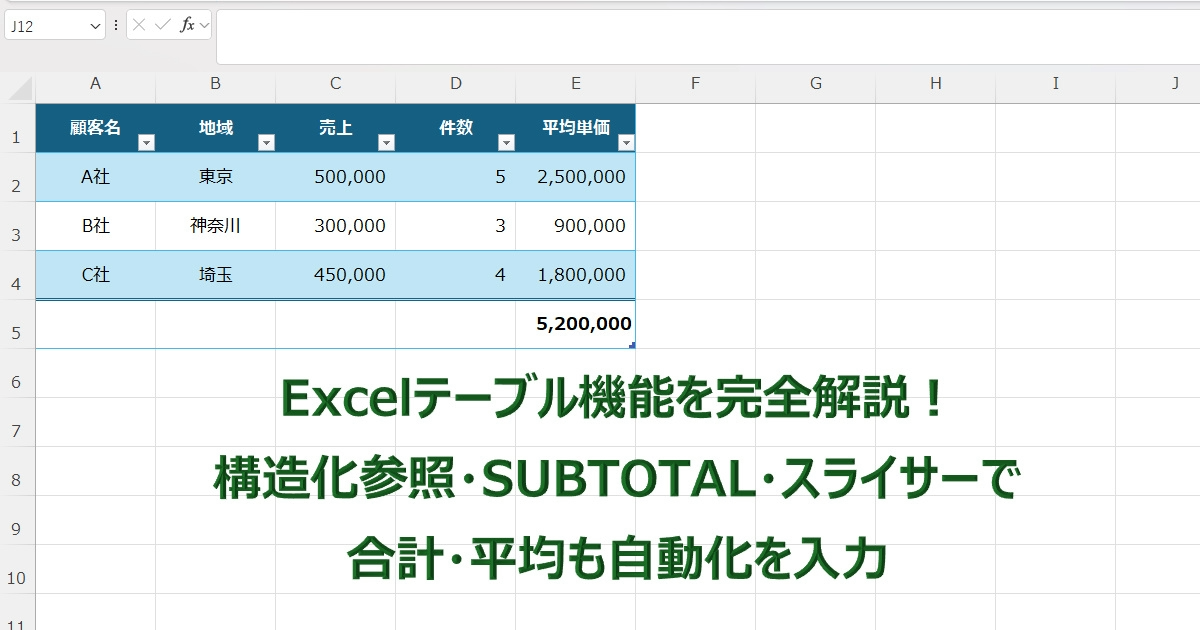
01. テーブルとは何か|「範囲」と「テーブル」の決定的な違い
まず、普通の「範囲」と「テーブル」の違いを3つ、整理しましょう。
違い① フィルターが自動で付く
範囲の場合、フィルター機能を使いたければ、毎回 データ > フィルター から有効にしなければいけません。
でもテーブルなら、1行目(ヘッダー行)に自動でフィルターボタン(▼)が付きます。最初からデータを絞り込む準備ができているわけです。
違い② 新しい行を追加すると、数式が自動で継承される
これがテーブルの最大の利点です。
普通の範囲で、列Dに「=A2+B2+C2」という数式があったとします。新しい行を追加したら? 手動でコピー&ペーストしなければ、新しい行には数式が入りません。
でもテーブルなら、新しい行を足した瞬間に、その行の数式が自動で追従します。ミス防止の仕組みが、最初から組み込まれているんです。
違い③ 参照時に「セル番地」ではなく「列名」が使える(構造化参照)
通常の数式:=SUM(A2:A100)
テーブルの数式:=SUM([売上])
テーブル内の列に名前が付くので、数式の可読性がグッと高まります。6ヶ月後に見返しても、「あ、売上を合計してるんだな」と一目瞭然です。
02. Ctrl+Tで30秒でテーブル化|最速の変換方法
では、実際にやってみましょう。
テーブル化の3ステップ
ステップ1:データ範囲内のセルをクリック
どこでもいいです。データが入ってる範囲内なら、どのセルを選んでも大丈夫。
ステップ2:Ctrl + T を押す
これだけです。30秒で完了。
(Mac をお使いの場合は Cmd + T)
その場で確認すべき3つのポイント
| 確認項目 | 何を見るか | 調整が必要な場合 |
|---|---|---|
| ヘッダー行 | 1行目が「列名」として認識されているか | 1行目がデータだった場合は、Ctrl+T をもう一度押して解除し、ヘッダー行を追加してから再度テーブル化 |
| テーブルの範囲 | 色が付いた範囲は、すべてのデータを含んでいるか | 右端や下端のデータが漏れていないか確認 |
| テーブル名 | デザイン タブ > テーブル名の欄に「Table1」などと表示されているか | 後で参照するときのために、わかりやすい名前(例:「顧客情報」「売上データ」)に変更するのが吉 |
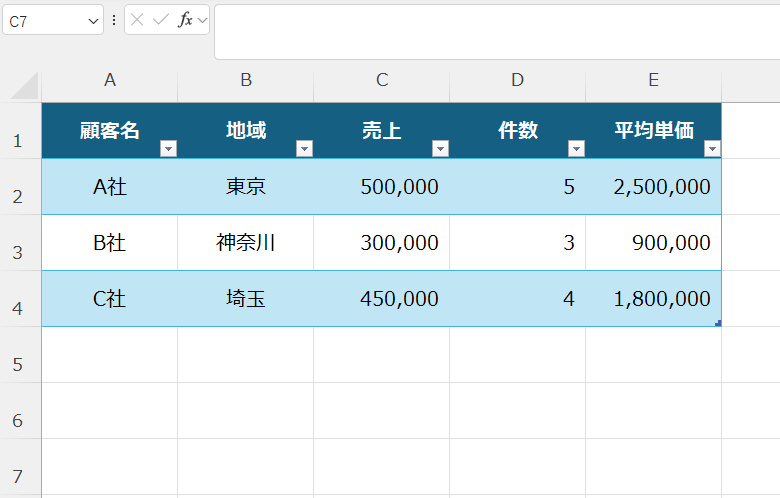
テーブル化「前後」の比較イメージ
【テーブル化前】普通の範囲
A B C D E
1 顧客名 地域 売上 件数 平均単価
2 A社 東京 500000 5 100000
3 B社 神奈川 300000 3 100000
4 C社 埼玉 450000 4 112500↓ Ctrl + T を押す ↓
【テーブル化後】テーブル状態
┌─────────────────────────────────────────────┐
│ 顧客名 地域 売上 件数 平均単価 │
│ ▼ ▼ ▼ ▼ ▼ │ ← フィルターボタンが自動で付く
├─────────────────────────────────────────────┤
│ A社 東京 500000 5 100000 │
│ B社 神奈川 300000 3 100000 │ ← 色付きで区別
│ C社 埼玉 450000 4 112500 │
└─────────────────────────────────────────────┘見た目の変化
- ✅ 1行目にフィルターボタン(▼)が自動で付く
- ✅ テーブル領域に色が付く(デフォルトは薄い青)
- ✅ 新しい行を追加すると、テーブルの色と計算式が自動で継承される
03. テーブルの4つの自動機能(基本)|テーブルのメリットが一目瞭然
テーブル化すると、以下の4つの自動機能が備わります。
機能①:自動フィルター
1行目のフィルターボタン(▼)をクリックすると、データを絞り込めます。
例えば、顧客名簿で「東京都」に絞って、ほかの都道府県は非表示にする。これだけで、必要なデータだけが見えるようになります。
機能②:数式の自動継承
新しい行を追加すると、既存の行の数式が、自動でその行にコピーされます。
例:売上データで、D列に「=A+B+C」という計算式がある場合、新しい行を足したら、その行のD列にも自動で計算式が入ります。ユーザーが追加しても、数式が漏れる心配がない わけです。
機能③:構造化参照(セル番地ではなく列名で参照)
テーブル内の数式では、=SUM(A2:A100) ではなく =SUM([売上]) と書けます。
後で見返すときに、何を計算してるのか一瞬で分かります。
機能④:スライサー(ボタン式フィルター)
ドロップダウンのフィルターより高級な「ボタン式フィルター」を追加できます。ポチッと押すだけで条件が切り替わり、複数のテーブルに同時適用することもできます。
ここからは、これらの機能を1つずつ、深掘りしていきます!
04. 構造化参照で数式をシンプルに|合計・平均の実例
テーブル内で数式を書く場合、構造化参照という特別な書き方を使います。
構造化参照の基本形
=SUM([列名])
=AVERAGE([列名])
=COUNTIF([列名], 条件)実例①:売上データの合計
テーブル「売上データ」に、「売上」という列があるとします。
普通の書き方
=SUM(B2:B1000)構造化参照での書き方
=SUM([売上])どちらでもいいのですが、後者の方が読みやすい のは明らかですよね。
実例②:複数の計算を組み合わせる場合
顧客単価の平均を求めたい場合
=AVERAGE([単価])顧客数をカウントしたい場合
=COUNTA([顧客名])特定の商品だけの合計を求めたい場合(例:「商品区分」が「A商品」の行だけ)
=SUMIF([商品区分], "A商品", [売上])このように、テーブルの列名を直接使える ので、複雑な数式でも意味が通りやすくなります。
構造化参照のメリット
| メリット | 説明 |
|---|---|
| 可読性 | セル番地を覚えなくて済む。「売上の合計」と一目瞭然 |
| 保守性 | テーブルの位置が変わっても、参照が壊れない |
| 拡張性 | 行を追加しても、構造化参照は自動で新しい行を含める |
構造化参照の視覚比較
【Excel 上での見え方】
┌─────────────────────────────────────────┐
│ 数式入力例 │
├─────────────────────────────────────────┤
│ 普通の書き方 │
│ =SUM(B2:B4) │
│ → セル番地を覚えている?うーん... │
│ │
│ 構造化参照での書き方 │
│ =SUM([売上]) │
│ → 「売上の合計」だ! │
└─────────────────────────────────────────┘計算内容と書き方の比較
| 計算内容 | 普通の数式 | 構造化参照 |
|---|---|---|
| 売上の合計 | =SUM(B2:B4) | =SUM([売上]) |
| 平均単価の平均 | =AVERAGE(E2:E4) | =AVERAGE([平均単価]) |
| 東京の売上だけ | =SUMIF(B2:B4, "東京", C2:C4) | =SUMIF([地域], "東京", [売上]) |
ポイント:右側の構造化参照は、セル番地を一切覚える必要がありません。列名があれば、複雑な計算でも「何をしているか」が一目瞭然です。
05. SUBTOTALとの組み合わせ(目から鱗)|フィルター後も正確に集計
ここが、テーブル機能の 真価を発揮する場面 です。
問題:普通のSUM関数はフィルター後も全行を集計してしまう
名簿テーブルで、「東京都」のデータだけをフィルターで表示したとします。
でも、セルに =SUM([売上]) と書くと、何が起きるか?
非表示の行も含めて、全国すべての売上を合計してしまいます。 これでは意味がありません。
解決策:SUBTOTAL関数を使う
=SUBTOTAL(109, [売上])SUBTOTAL 関数の第1引数に特定の番号を指定すると、非表示の行を無視して計算 してくれます。
SUBTOTAL関数の主な使い方
| 番号 | 関数 | 説明 |
|---|---|---|
| 9 | SUM(非表示行を無視) | 見えてる行だけの合計 |
| 109 | SUM(非表示行を無視) | 9と同じだが、手動フィルタ結果だけ対象 |
| 1 | AVERAGE(非表示行を無視) | 見えてる行だけの平均 |
| 101 | AVERAGE(非表示行を無視) | 1と同じだが、手動フィルタ結果だけ対象 |
| 3 | COUNTA(非表示行を無視) | 見えてる行の個数カウント |
| 103 | COUNTA(非表示行を無視) | 3と同じだが、手動フィルタ結果だけ対象 |
実務での使い分け
例①:落札情報で「A市」だけの合計を見たい
=SUBTOTAL(109, [落札金額])フィルターで「A市」に絞ると、その市の合計だけが表示されます。
例②:名簿で「営業部」の平均給与を見たい
=SUBTOTAL(1, [給与])部署でフィルターすれば、その部署だけの平均が出ます。
例③:在庫一覧で「在庫あり」の商品数だけを数えたい
=SUBTOTAL(3, [商品名])「在庫状況」でフィルターして「在庫あり」だけ表示すれば、その数がカウントされます。
重要なポイント
SUBTOTALと構造化参照を組み合わせると、フィルター後の動的集計が自動でできます。 つまり、ユーザーがフィルターボタンで条件を変えるたびに、集計結果がリアルタイムで変わるわけです。
SUBTOTALの動作イメージ(フィルター前後)
【フィルター前】全データが表示されている状態
┌────────────────────────────────────────┐
│ 地域 ▼ | 売上 │
├────────────────────────────────────────┤
│ 東京 | 500,000 │
│ 神奈川 | 300,000 │
│ 埼玉 | 450,000 │
├────────────────────────────────────────┤
│ 合計:=SUBTOTAL(109, [売上]) │
│ 結果 → 1,250,000 │
└────────────────────────────────────────┘↓ 地域フィルターで「東京」だけを選択 ↓
【フィルター後】東京のデータだけが表示されている状態
┌────────────────────────────────────────┐
│ 地域 ▼ | 売上 │
├────────────────────────────────────────┤
│ 東京 | 500,000 ← 東京だけが見える │
│ (他の行は非表示) │
├────────────────────────────────────────┤
│ 合計:=SUBTOTAL(109, [売上]) │
│ 結果 → 500,000 ← 自動で更新! │
└────────────────────────────────────────┘何が起きているか
- フィルター前:全行(東京 + 神奈川 + 埼玉)を合計 → 1,250,000
- フィルター後:見えてる行(東京だけ)を合計 → 500,000
- SUBTOTAL関数は、非表示の行を自動で無視 してくれるので、手動で計算し直す必要がない
【実際のExcel画面での構造化参照の例】
上記のように、テーブル下部のセルに =SUBTOTAL(109, [平均単価]) と入力すると、構造化参照で「平均単価」列全体を参照します。フィルターボタンで地域を絞ると、合計値がリアルタイムで更新されます。
06. スライサーで高級ダッシュボード化|複数テーブルに同じボタン適用
ここからは、見た目も機能も高級感が出る テクニックです。
スライサーとは
フィルターボタン(▼)は地味ですが、スライサー は、ポチッと押すだけで条件が変わるボタン式フィルターです。
例えば「東京」「神奈川」「埼玉」といったボタンが画面に並んで、クリックするだけで該当データを抽出できます。
スライサーの作成方法
ステップ1:テーブルを選択
テーブル内のセルをどれか選んでください。
ステップ2:デザイン タブ > スライサーの挿入
ダイアログが出たら、フィルター対象にしたい列(例:「都道府県」)を選びます。
ステップ3:ボタンが配置される
画面上に「東京」「神奈川」「埼玉」といったボタンが並びます。
スライサーの真価:複数のテーブルに同時適用
スライサーの本領は、ここです。
例えば、以下の2つのテーブルがあるとします。
- テーブルA:「顧客マスタ」(顧客情報)
- テーブルB:「売上記録」(実績データ)
通常なら、Aと Bに別々にフィルターをかけなければいけません。
でも、スライサーなら、1つのボタンクリックで両方のテーブルが同時に絞り込まれます。
これにより、複数のテーブルの関連データを同じ条件で見比べることができるんです。
スライサーで作るダッシュボードの実例
| 配置 | 内容 |
|---|---|
| 左側 | スライサーボタン(都道府県別)→「東京」をクリック |
| 中央 | 顧客マスタテーブル → 東京の顧客だけ表示 |
| 右側 | 売上記録テーブル → 東京の売上だけ表示 |
| 下部 | 合計・平均の集計表 → 自動で東京だけの数字に更新 |
ダッシュボードのレイアウト図
┌─────────────────────────────────────────────────────────┐
│ スライサーボタン(地域選択) │
│ ┌────────┐ ┌────────┐ ┌────────┐ │
│ │ 東京 │ │神奈川 │ │ 埼玉 │ ← 「東京」をクリック │
│ └────────┘ └────────┘ └────────┘ │
└─────────────────────────────────────────────────────────┘
↓ スライサーがテーブルA・Bに同時適用
┌────────────────────────────┬────────────────────────────┐
│ テーブルA:顧客マスタ │ テーブルB:売上記録 │
├────────────────────────────┼────────────────────────────┤
│ 顧客名▼ | 地域 | 売上 │ 日付▼ | 顧客 | 売上額 │
│ A社 | 東京 | 500,000 │ 2024/1 | A社 | 300,000 │
│ D社 | 東京 | 600,000 │ 2024/2 | A社 | 200,000 │
│ (神奈川・埼玉は非表示) │ 2024/3 | D社 | 400,000 │
│ │ (神奈川・埼玉は非表示)│
└────────────────────────────┴────────────────────────────┘
↓ 両テーブルが同時に「東京」に絞られている
┌─────────────────────────────────────────────────────────┐
│ 集計結果(自動更新) │
├─────────────────────────────────────────────────────────┤
│ 顧客数:2 | 合計売上:1,100,000 | 平均:550,000 │
└─────────────────────────────────────────────────────────┘ポイント
- スライサーボタン「東京」をクリック
- テーブルA と テーブルB が 同時に東京データに絞られる
- 下部の集計結果が 自動で更新される
- これで、複数データを同じ条件で比較分析できる
07. テーブル + ピボットテーブル の無敵コンボ|ソーステーブルの変更が自動反映
次に、テーブルとピボットテーブルの相性 について解説します。
通常の問題:ピボットテーブルのソースデータが増えても、自動更新されない
ピボットテーブルは、データをドラッグ&ドロップで集計できる便利な機能です。
でも、ソースのデータ範囲が決まっているため、新しい行を追加しても、ピボットテーブルに反映されません。 毎回、手動で更新(F9キー)しなければいけないんです。
解決策:ピボットテーブルのソースを「テーブル」にする
ピボットテーブルを作るときに、ソースデータとしてテーブルを指定すると、以下が起きます。
- テーブルに新しい行が追加されると、ピボットテーブルが自動で検知する
- 手動で「更新」する必要がなくなる
- 営業データが毎日追加される現場では、この自動反映が 時間を大幅に短縮 してくれます
実例:日々の売上データを集計する場合
毎日のワークフロー
- 営業担当者が「売上記録」テーブルに新しい行を追加
- ピボットテーブル(ソースは「売上記録」)が自動で新データを認識
- 部長が見るダッシュボードの数字が、自動で最新に更新される
手作業の削減時間
- 月に20営業日 × 毎回5分の更新作業 = 月100分削減!
これが、テーブルを使う実務的なメリットです。
08. 実務マルチシーン活用例|名簿・落札・在庫での合計・平均・カウント計算
では、実際の職場で、どのような場面でテーブルが活躍するか、具体例を見てみましょう。
シーン①:顧客名簿管理|顧客の追加と平均購買額の自動更新
データ構成
| 顧客名 | 地域 | 購買額 | 購買回数 | 単価 |
|---|---|---|---|---|
| A社 | 東京 | 500,000 | 5 | 100,000 |
| B社 | 神奈川 | 300,000 | 3 | 100,000 |
| C社 | 埼玉 | 450,000 | 4 | 112,500 |
テーブル化して実現できること
- 新しい顧客を追加すると、「単価」の計算式(=購買額/購買回数)が自動で入る
- スライサーで地域を「東京」に絞ると、東京の平均購買額が自動で計算される
=SUBTOTAL(1, [購買額])で、フィルター後の平均購買額を表示
効果:営業が毎日顧客を追加するたびに、あなたが数式をコピーしなくていい。
テーブル化の実装イメージ
┌─────────────────────────────────────────────┐
│ 顧客名▼ | 地域▼ | 購買額 | 購買回数 | 単価 │
├─────────────────────────────────────────────┤
│ A社 | 東京 | 500,000 | 5 | 100,000 │
│ B社 | 神奈川| 300,000 | 3 | 100,000 │
│ C社 | 埼玉 | 450,000 | 4 | 112,500 │
│ │ │ │ │ ← 新規行 │
│ │ │ │ │ 自動計算 │
└─────────────────────────────────────────────┘
集計結果
平均購買額(東京だけ)= SUBTOTAL(1, [購買額]) = 500,000新規顧客を追加した場合
D社を追加 → 「単価」の計算式が自動で入る
→ 購買額 / 購買回数 = 自動計算完了
→ 数式漏れなし!シーン②:落札情報の管理|発注者別・市町村別の集計
データ構成
| 発注者 | 市町村 | 落札金額 | 業者数 | 平均札価 |
|---|---|---|---|---|
| A省 | 東京都 | 100,000,000 | 15 | 6,666,667 |
| B局 | 神奈川県 | 85,000,000 | 12 | 7,083,333 |
| C市 | 埼玉県 | 45,000,000 | 8 | 5,625,000 |
テーブル化して実現できること
- 新しい落札情報を追加すると、「平均札価」が自動で計算される
- 市町村別にフィルターして、その市の合計落札金額を
=SUBTOTAL(109, [落札金額])で表示 - 複数の落札テーブルを、同じスライサー(市町村別)で連動させて、比較分析
効果:国土交通省の発注情報を毎日スクレイピングで取得する際に、テーブルに追加するだけで集計が自動更新される。
落札情報テーブルの実装イメージ
┌──────────────────────────────────────────────────────┐
│ 発注者▼ | 市町村▼ | 落札金額 | 業者数 | 平均札価 │
├──────────────────────────────────────────────────────┤
│ A省 | 東京都 | 100M | 15 | 6,666,667 │
│ B局 | 神奈川県| 85M | 12 | 7,083,333 │
│ C市 | 埼玉県 | 45M | 8 | 5,625,000 │
└──────────────────────────────────────────────────────┘
市町村フィルター後(東京都のみ表示)
合計落札金額 = SUBTOTAL(109, [落札金額]) = 100,000,000毎日の運用フロー
1. 国土交通省HPから最新の発注データを取得
2. テーブルに新しい行を追加
3. 「平均札価」(落札金額/業者数)が自動計算
4. スライサーで市町村を選択 → 合計・平均が自動更新
5. レポート完成(集計作業ゼロ)シーン③:在庫管理|商品ごとの在庫額と回転率
データ構成
| 商品名 | 商品区分 | 在庫数 | 単価 | 在庫額 | 月売上 | 回転率 |
|---|---|---|---|---|---|---|
| 商品X | A区分 | 50 | 10,000 | 500,000 | 100,000 | 0.2 |
| 商品Y | B区分 | 120 | 5,000 | 600,000 | 150,000 | 0.25 |
| 商品Z | A区分 | 30 | 15,000 | 450,000 | 200,000 | 0.44 |
テーブル化して実現できること
- 新商品を追加すると、「在庫額」(在庫数 × 単価)と「回転率」(月売上 / 在庫額)が自動計算
- 商品区分で絞ると、その区分の平均回転率が
=SUBTOTAL(1, [回転率])で表示 - 「在庫額が100万円以上」の商品だけを手動でフィルターして、過剰在庫をリスト化
効果:月初に倉庫から新しい在庫情報をもらったら、テーブルに貼り付けるだけで、全ての計算が完了。
在庫管理テーブルの実装イメージ
┌────────────────────────────────────────────────────────┐
│ 商品名▼ | 区分▼ | 在庫数 | 単価 | 在庫額 | 月売上 | 回転率 │
├────────────────────────────────────────────────────────┤
│ 商品X | A区分 | 50 | 10K | 500K | 100K | 0.2 │
│ 商品Y | B区分 | 120 | 5K | 600K | 150K | 0.25 │
│ 商品Z | A区分 | 30 | 15K | 450K | 200K | 0.44 │
└────────────────────────────────────────────────────────┘
商品区分フィルター(A区分のみ表示)
平均回転率 = SUBTOTAL(1, [回転率]) = 0.32
→ 「A区分は月1回転以下 = 過剰在庫」と判断月初の在庫更新フロー
1. 倉庫から「在庫数」データを取得
2. テーブルに行を追加(「商品名」「在庫数」「単価」を入力)
3. 「在庫額」(在庫数×単価)が自動計算
4. 「回転率」(月売上/在庫額)が自動計算
5. 過剰在庫(回転率 < 0.3)を手動フィルター
6. 在庫削減策の検討資料が完成共通のメリット
| メリット | 説明 |
|---|---|
| 追加時のミス防止 | 新規データを追加しても、計算式が漏れない |
| フィルター後の正確な集計 | SUBTOTALで見えてる行だけ合計・平均 |
| 動的ダッシュボード | スライサーで条件を変えるたびに、集計が自動更新 |
| データの信頼性 | 手動計算がないので、ケアレスミスがなくなる |
09. テーブル解除・一時的な範囲変換|加工後の調整方法
テーブル化の過程で、「一度テーブルにしてから、加工後に普通の範囲に戻したい」という場面が出てきます。
例えば、別シートにコピペするときに、元のシートのテーブルを一時的に範囲に戻す場合ですね。
テーブルを範囲に変換する手順
方法①:右クリックで解除(最も簡単)
- テーブル内のセルを選択
- 右クリック
- 「テーブル」→「範囲に変換」をクリック
方法②:デザイン タブから解除
- テーブル内のセルを選択
- デザイン タブ > ツール欄 > 「範囲に変換」
これだけです。すぐに普通の範囲に戻ります。
その後、もう一度テーブル化したい場合は Ctrl + T(Mac は Cmd + T)を押してください。
解除後の注意点
| 注意点 | 対処法 |
|---|---|
| 構造化参照が壊れる | テーブルが範囲に変わると、[列名] の参照は自動で A2:A100 のようなセル番地に変換される。参照先を確認して問題なければそのまま |
| スライサーが消える | テーブル化時に作ったスライサーボタンは削除される。不要ならそのままでOK |
| 数式継承がなくなる | 範囲に戻ると、新しい行を追加しても数式は継承されない。その後の作業を想定して判断を |
パターン別の対応
パターン①:別シートにコピペするために一時的に解除
元シート:テーブル化(Ctrl+T)→加工→「範囲に変換」→コピペ→
(必要に応じて)「元に戻す」(Ctrl+Z)でテーブル状態に復帰パターン②:値貼り付けするために解除
加工後に「範囲に変換」してから、別シートに「値のみ」貼り付けすれば、テーブル形式にはなりません。
パターン③:長期的に範囲で使い続ける
「範囲に変換」した後、そのまま保存。ただし、その場合は数式の継承がないので、今後手動でコピーが必要です。
10. よくあるエラーと対処法|万が一のときも慌てない
テーブル化がうまくいかないことも、稀にあります。よくあるパターンと対処法をまとめました。
エラー①:「1行目がヘッダーと認識されず、データとして扱われている」
症状:テーブル化したら、1行目のセルに「1」「2」「3」という自動番号が付いてしまった。
原因:1行目が列名ではなく、データとして認識されている。
対処法:
- Ctrl + T をもう一度押して、テーブルを解除
- 1行目に適切な列名を入力(例:「顧客名」「売上」「地域」)
- もう一度 Ctrl + T でテーブル化
エラー②:「テーブルの範囲が、データの一部しか含んでいない」
症状:右端や下端のデータがテーブルに含まれておらず、フィルターボタンが表示されていない列がある。
原因:データ範囲内のセル選択が中途半端だった。
対処法:
- 一度 Ctrl + T をもう一度押して、テーブルを解除
- データ全体を含むセル(例:A1)を選択
- Ctrl + T で再度テーブル化
- もし数列が足りなければ、デザイン タブ > テーブルのサイズ変更 で範囲を拡張
エラー③:「構造化参照が『#NAME?』エラーになっている」
症状:セルに =SUM([売上]) と入力したら、「#NAME?」エラーが出た。
原因:
- テーブルの列名が、入力した名前と一致していない(例:テーブルの列名は「売上」だが、「売上額」と入力した)
- テーブル内ではなく、テーブル外のセルで構造化参照を使おうとしている
対処法:
- テーブルの列名を確認(デザイン タブ > テーブル内の列をクリック)
- 正確な列名をコピペして数式に貼り付け
- もし、テーブル外で構造化参照を使いたければ、テーブル名を明記:
=SUM(顧客情報[売上])
エラー④:「スライサーをクリックしても、フィルターが反映されない」
症状:スライサーで「東京」をクリックしたのに、全国のデータが表示されたままになっている。
原因:スライサーが、テーブルではなく、別のピボットテーブルに接続されている。
対処法:
- スライサーを右クリック
- 「データソースの管理」を開く
- 「テーブル」と「ピボットテーブル」の接続を確認
- 必要なら、テーブル側に接続し直す
まとめ|テーブル機能は「今やるか後でやるか」の選択肢
Excelのテーブル機能は、「やるべきか」ではなく「今やるか、後でやるか」という選択肢 です。
この記事で学んだこと(振り返りチェックリスト)
- ✅ テーブル化は Ctrl+T で30秒
- ✅ テーブルなら、新しい行を追加しても数式が自動で継承される
- ✅ 構造化参照
[列名]で、複雑な数式もシンプルに - ✅ SUBTOTAL関数で、フィルター後も正確な合計・平均・カウントができる
- ✅ スライサーで複数テーブルを同時フィルター → 高級ダッシュボード完成
- ✅ ピボットテーブルのソースがテーブルなら、自動で最新データを反映
- ✅ 一時的に範囲に変換することもできる(テーブル解除)
- ✅ エラーは落ち着いて対処すれば、ほぼ解決できる
今日やるべき最小アクション
まずは、今使ってるファイルの中で、データ範囲が一つ選んで、Ctrl+T を押してみてください。 これだけです。
テーブル化した直後に、以下の3つを試してみましょう
- フィルターボタンをクリック して、データを絞り込む快感を感じる
- 新しい行を追加 して、計算式が自動で継承されるのを確認
- 計算式を
=SUM([列名])の形に書き換えて、シンプルさを実感
この小さな成功体験が、「あ、これ使えるな」という気づきになります。
次のステップ(余裕が出たらチャレンジ)
- 複数のテーブルにスライサーを設定して、ダッシュボード化に挑戦
- SUBTOTAL関数を使って、動的な集計表を作成
- ピボットテーブルのソースをテーブルに変更して、自動更新の快感を味わう
テーブル機能は、一度使い始めたら、もう「普通の範囲」には戻れません。仕事が本当にラクになります。
あなたのフィードバックが次の記事のヒントになります。「テーブルでこんなことがしたい」「ここが分からなかった」というご質問があれば、ぜひお聞かせください。
あせらず、くさらず、あきらめず。まずは一歩、テーブルの世界に足を踏み入れてみてくださいね!
コメント